案例【中国象棋人机对战】引入了AI算法,学习低代码和高代码如何混编并互相调用
以低代码和高代码(原生JS代码)混编的方式引入了AI算法,学习如何使用表达式调用原生代码的。
整个过程在众触低代码应用平台进行,适合高阶学员。
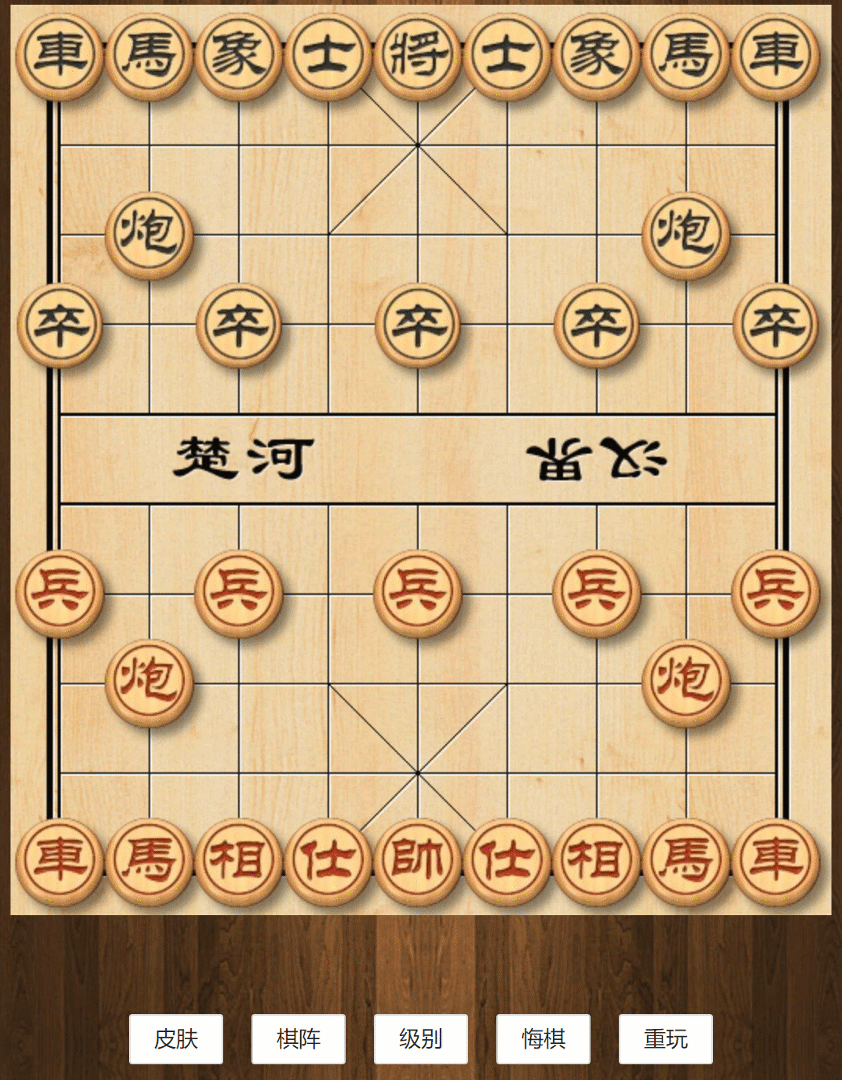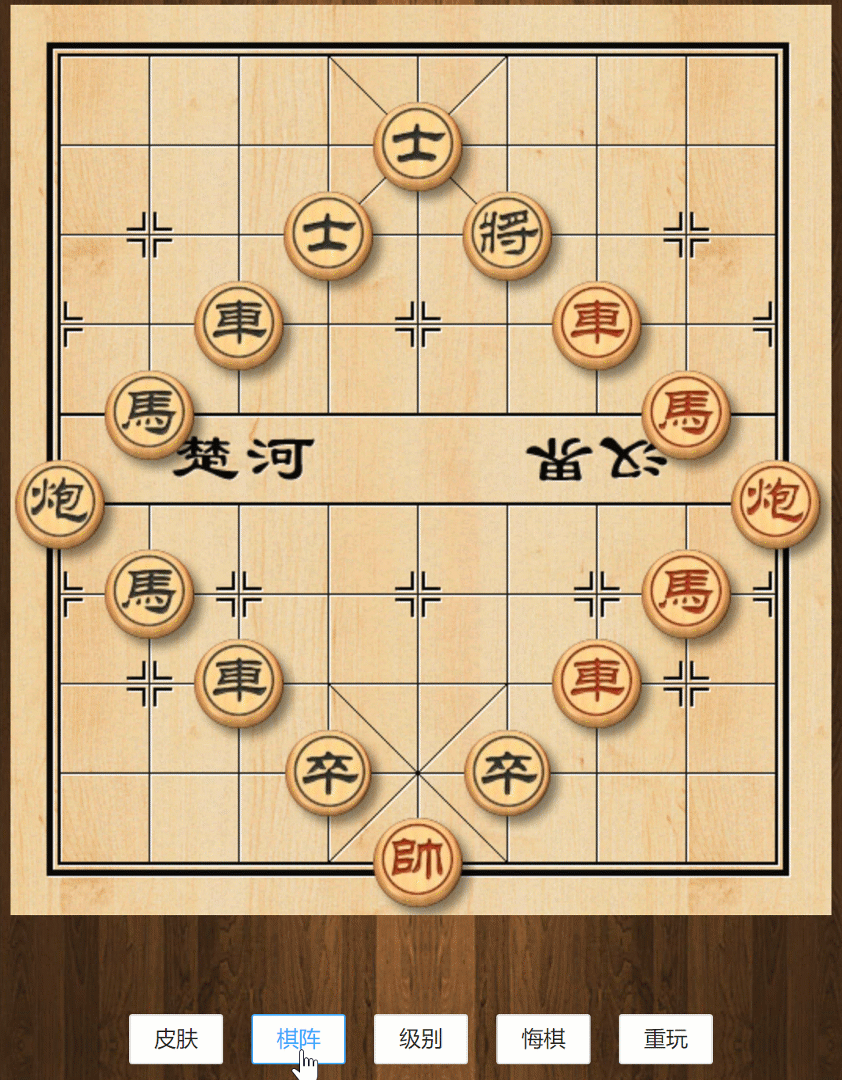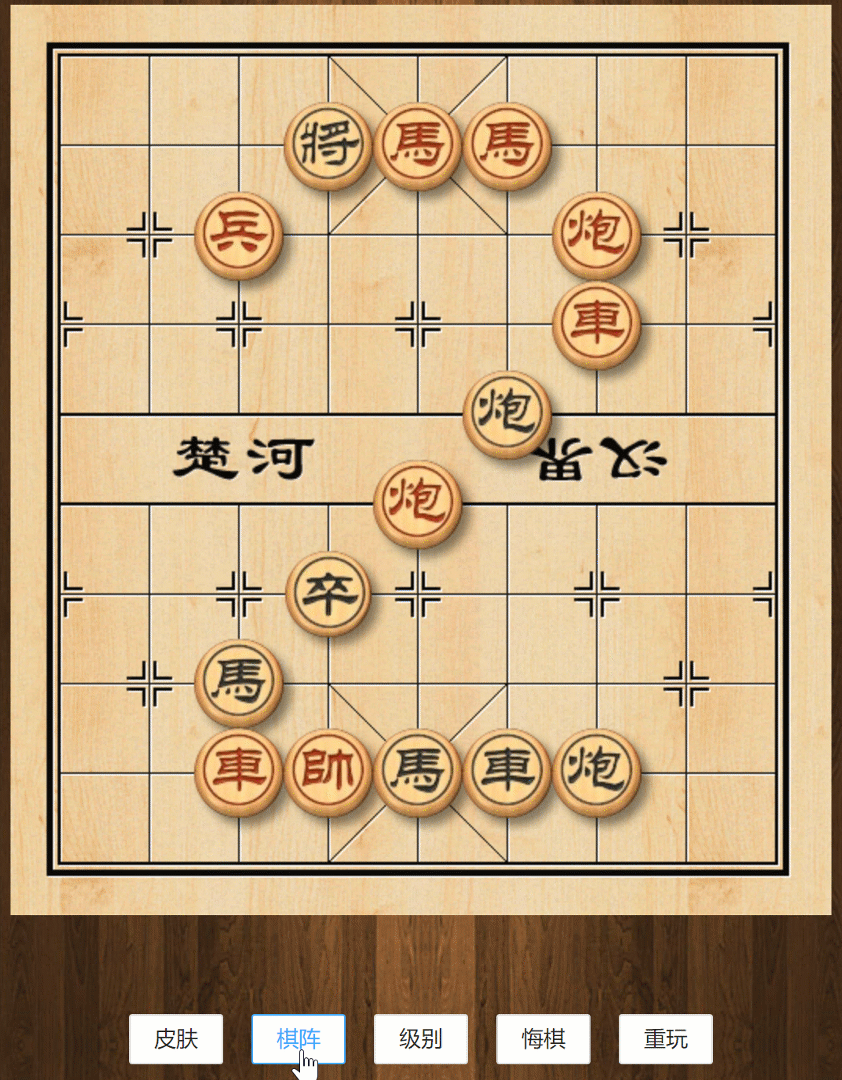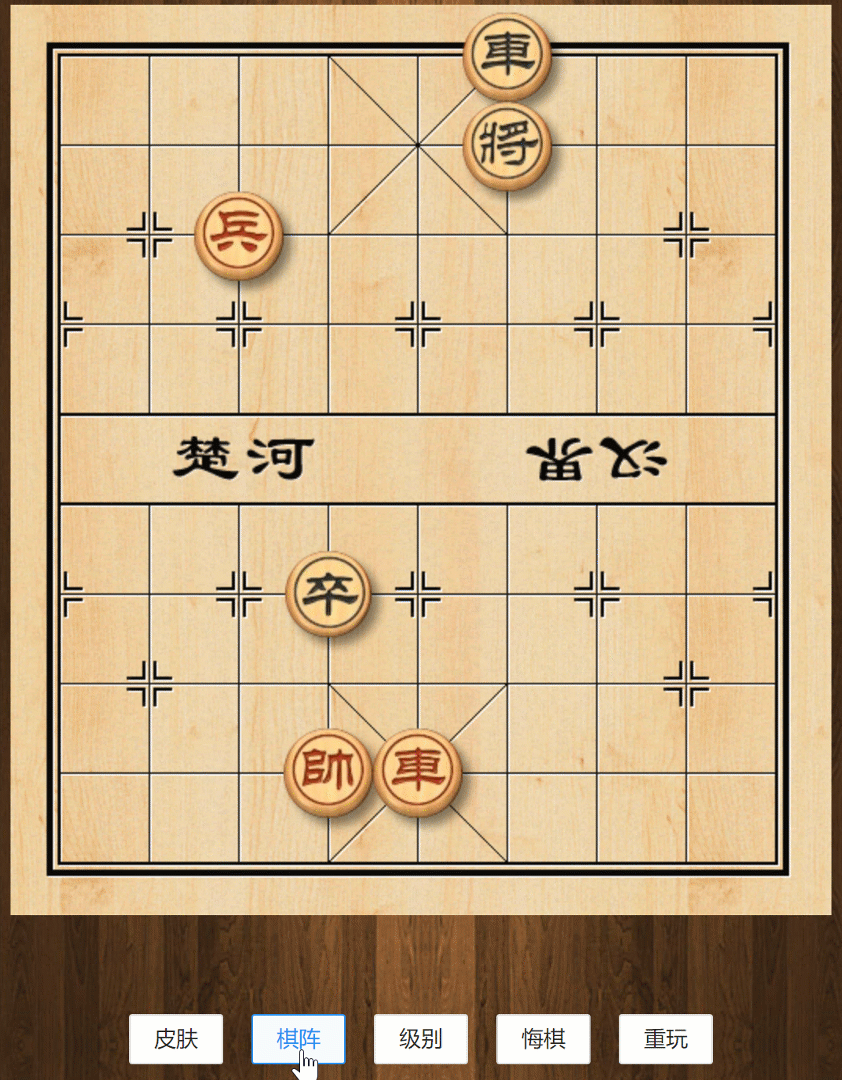
AI智能级别演示
AI算法分三个等级,体现出来的智能水平不同。
切换皮肤
切换棋阵
各棋子的走法规则

先动手玩一玩:https://chinese-chess.zc-app.cn/z
详尽的的教学请移步哔哩哔哩视频:https://www.bilibili.com/video/BV1e44y1j7Ab
初始数据
ready里:
$v.设置 = {AI搜索深度: 3, 外观: { cur: 1, arr: ["stype1", "stype2", "stype3"] }, 棋阵: { cur: 0, arr: ["初始阵", "八卦阵", "七星阵", "很二阵", "测试"] }}
$v.F5 = 1$c.obj.棋子
 大写字母的是对方黑子(my为-1,表示非我方),小写字母的是我方红子(my为1)。
大写字母的是对方黑子(my为-1,表示非我方),小写字母的是我方红子(my为1)。
【图】表示棋子图片URL的位置。因为所有图片都是放在一个文件夹整理好了整体上传的,位置都固定的。
$c.obj.棋阵
 认真观察初始阵(标准棋盘)和图二里面棋子的布阵,不难发现它们的对应关系。
认真观察初始阵(标准棋盘)和图二里面棋子的布阵,不难发现它们的对应关系。
$c.obj.估值
各棋子在棋阵中不同位置的估值,是AI走棋的依据,AI用这个来评估一个棋子应该如何走才能得到更高的价值。
$c.obj.ui
里面预设了3种UI样式,根据其预设图片位置通过new $w.Image()生成所有棋子及着点、外框、棋盘的图片。只有图片加载完成了才能进行桌布的绘制,所以在最后一个图片的onload函数里调用$c.exp.绘制。
画布与刷新
一个空画布canvas放在挂载组件里,挂载组件的【重新挂载表达式】设为$v.F5,当$v.F5的值发生变化时会触发挂载事件,挂载事件里会进行初始化$c.exp.初始化.exc()。
切换皮肤、棋阵、级别,重玩都是改变某个设置后改变$v.F5的值卸载后重新初始化的。
初始化
...
$v.画布.addEventListener("click", func($c.exp.走棋))
...
$c.exp.摆棋子.exc()
// 黑子为红字估值位置的倒置
$l.黑子 = ["C","M","X","S","J","P","Z"]
$l.黑子.forEach('$c.obj.估值[$x] = clone($c.obj.估值[$x.toLowerCase()]).reverse()')
$w.AI = { 估值: $c.obj.估值 }
$w.eval($c.js.AI)
$w.eval($c.js.走法)画布上添加有click事件监听器,点击时开始走棋。
$c.obj.估值预设了红子的估值,把它位置颠倒一下就成了黑子的估值。颠倒前要记得clone一下才不会打乱原来的数据。
在AI走棋时会大量计算各种走法的估值,走法函数被调用的次数非常多。瞬间被海量调用的函数应该优先考虑原生代码而非表达式以提高速度,所以把它放在$c.js.走法中。
我们把AI算法相关的放在window.AI下以方便调用。注意观察$c.js.AI里面的原始JS代码有AI.走棋、AI.AB搜索和AI.评估棋阵三个函数,通过$w.eval($c.js.AI)执行一下,这三个函数就都放在$w.AI里了($w就是window的简写)。
摆棋子
根据其在棋阵中的位置生成各个棋子。
$v.棋子 = {}
$v.棋阵.forEach('$x.forEach("$x ? $v.棋子[$x] = $w.Object.assign({x: $i, y: $p.$i, key: $x, 名: $x.slice(0,1)}, $c.obj.棋子[$x.slice(0,1)]) : null")')走棋
根据点击位置计算出其在棋盘中的坐标(x、y轴)。
$args是click监听器传进来的参数,$arg就是第一个参数$args[0]了。
如果坐标不在棋盘内就忽略点击动作。
stopIf($v.结束)
$l.x = $w.Math.round(($arg.pageX - $v.画布.offsetLeft() - $v.ui.pointStartX - 20) / $v.ui.spaceX)
$l.y = $w.Math.round(($arg.pageY - $v.画布.offsetTop() - $v.ui.pointStartY - 20) / $v.ui.spaceY)
stopIf($l.x < 0 || $l.x > 8 || $l.y < 0 || $l.y > 9)
$l.棋子 = $v.棋阵[$l.y][$l.x]
$l.棋子 ? $l.棋子 = $v.棋子[$l.棋子] : ""
$l.棋子 ? ($l.棋子.my == 1 ? $c.exp.选子.exc() : ($v.已选 && $v.已选.key !== $l.棋子.key ? $c.exp.吃子.exc() : "")) : ($v.着点.find('$x[0] == $l.x && $x[1] == $l.y') ? $c.exp.落子.exc() : "")如果点击的是我方棋子则执行【选子】动作,给已选棋子添加外框,根据已选棋子在棋阵中的位置执行走法计算得出其所有着点。
选子
$v.已选 = $l.棋子
$v.外框 = { x: $v.已选.x, y: $v.已选.y }
$v.着点 = $w.走法[$v.已选.走法]($v.棋阵, $v.棋子, $v.已选.my, $v.已选.x, $v.已选.y)
$c.exp.绘制.exc()
$v.选子声.play()如果点击的是对方棋子且在上次已选棋子的着点上则执行【吃子】动作
吃子
把走棋路径推入【历史】中,并把两个棋子的位置添加外框。
删除原棋子在棋阵中的位置并把新位置换成我方棋子。
删除被吃棋子并把原已选棋子的位置挪到新位置。
如果被吃的是【将】则结束。
稍等片刻后开始【AI走棋】(因为AI走得太快人反应不过来)。
stopIf(!$v.着点.find('$x[0] == $l.x && $x[1] == $l.y'), 'log("吃不到哦!")')
$v.历史.push([$v.已选.x, $v.已选.y, $l.x, $l.y])
$v.棋阵[$v.已选.y][$v.已选.x] = undefined
$v.棋阵[$l.y][$l.x] = $v.已选.key
$v.棋子[$l.棋子.key] = undefined
$v.外框 = { x: $v.已选.x, y: $v.已选.y, x2: $l.x, y2: $l.y }
$v.已选.x = $l.x
$v.已选.y = $l.y
$v.已选 = undefined
$v.着点 = []
$c.exp.绘制.exc()
$v.点击声.play()
$l.棋子.走法 == "j" ? (alert($l.棋子.my == 1 ? "你赢了!" : "你输了!"); $v.结束 = true) : ""
timeout(50)
$c.exp.AI走棋.exc()如果点击的不是棋子但是在已选棋子的着点上则执行【落子】动作
落子
$v.棋阵[$v.已选.y][$v.已选.x] = undefined
$v.棋阵[$l.y][$l.x] = $v.已选.key
$v.历史.push([$v.已选.x, $v.已选.y, $l.x, $l.y])
$v.外框 = { x: $v.已选.x, y: $v.已选.y, x2: $l.x, y2: $l.y }
$v.已选.x = $l.x
$v.已选.y = $l.y
$v.已选 = undefined
$v.着点 = []
$c.exp.绘制.exc()
$v.点击声.play()
timeout(50)
$c.exp.AI走棋.exc()类似【吃子】动作
悔棋
就是重置整个棋阵棋子,根据【历史】的足迹重走一遍,直到最后两步。
走到最后一步时添加外框。
$v.棋阵 = clone($c.obj.棋阵[$v.设置.棋阵.arr[$v.设置.棋阵.cur % 5]])
$c.exp.摆棋子.exc()
$v.历史.pop()
$v.历史.pop()
$v.历史.forEach('$l.走子 = $v.棋阵[$x[1]][$x[0]]; $l.吃子 = $v.棋阵[$x[3]][$x[2]]; $l.吃子 ? $v.棋子[$l.吃子] = undefined : ""; $v.棋子[$l.走子].x = $x[2]; $v.棋子[$l.走子].y = $x[3]; $v.棋阵[$x[3]][$x[2]] = $l.走子; $v.棋阵[$x[1]][$x[0]] = undefined; $v.历史.length - 1 ? $v.外框 = { x: $x[0], y: $x[1], x2: $x[2], y2: $x[3] } : ""')
$c.exp.绘制.exc()AI走棋
$v.AI着 = $w.AI.走棋(clone($v.棋阵), clone($v.棋子), $v.设置.AI搜索深度, -1)
stopIf(!$v.AI着, 'alert("你赢了!"); $v.结束 = true')
$v.历史.push($v.AI着)
$l.已选 = $v.棋阵[$v.AI着[1]][$v.AI着[0]]
$l.已选 ? $l.已选 = $v.棋子[$l.已选] : ""
$l.被吃 = $v.棋阵[$v.AI着[3]][$v.AI着[2]]
$c.exp[$l.被吃 ? "AI吃子" : "AI落子"].exc()
$c.exp.绘制.exc()
$v.点击声.paused ? "" : timeout(300)
$v.点击声.paused ? "" : timeout(300)
$v.点击声.play()前面初始化的时候我们有把原生代码【AI.走棋】$w.eval()以后放在$w里面了,这里直接执行原生代码的【$w.AI.走棋】得到AI认为的最佳着点。(总结:众触表达式和原生代码是通过window这个媒介来互相认识并调用的)
如果没得到着点则AI已被将死。
如果着点上是我方棋子则执行【AI吃子】,否则执行【AI落子】
AI吃子
$v.棋阵[$v.AI着[1]][$v.AI着[0]] = undefined
$v.棋阵[$v.AI着[3]][$v.AI着[2]] = $l.已选.key
$l.已选.x = $v.AI着[2]
$l.已选.y = $v.AI着[3]
$v.外框 = { x: $v.AI着[0], y: $v.AI着[1], x2: $v.AI着[2], y2: $v.AI着[3] }
$l.被吃 == "j0" || $l.被吃 == "J0" ? (alert($v.棋子[$l.被吃].my == -1 ? "你赢了!" : "你输了!"); $v.结束 = true) : ""
$v.棋子[$l.被吃] = undefinedAI落子
$v.棋阵[$v.AI着[1]][$v.AI着[0]] = undefined
$v.棋阵[$v.AI着[3]][$v.AI着[2]] = $l.已选.key
$v.外框 = { x: $v.AI着[0], y: $v.AI着[1], x2: $v.AI着[2], y2: $v.AI着[3] }
$l.已选.x = $v.AI着[2]
$l.已选.y = $v.AI着[3]如果你打开原生代码学习AI搜索算法,估计很难明白它是如何实现人工智能的,下面摘抄了一点AI搜索算法原理供选学用。
极大极小搜索
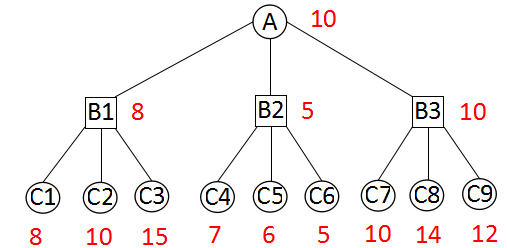
圆形节点为红方走棋的局面,方形节点为黑方走棋局面,红色数字为局面估值(也就是红方的优势)。深度优先遍历这个搜索树。
初始局面为A,该红方走棋。红方有B1、B2、B3三种走法。
假设红方选择第一种走法,走到了局面B1。
在局面B1,该黑方走棋。黑方有C1、C2、C3三种走法。
C1、C2、C3是叶子节点,调用局面评估函数,算得局面估值(也就是红方优势)分别是8、10、15。
回到局面B1,此时该黑方走棋。黑方后完后,红方优势越小,对黑方越有利。黑方自然会走到对自己最有利的C1局面。此时我们认为,B1局面的估值是8。
同样的方法,B2、B3的估值分别是5、10。
回到初始局面A,红方走棋。现在已经知道,选择第一种走法,最终估值为8;选择第二种走法,最终估值为5;选择第三种走法,最终估值为10。估值就是红方的优势,红方自然会选择对自己优势最大的走法,也就是走到局面B3。
可知行棋路线为A -> B3 -> C7。
A点选择估值最大的局面,称为极大点;B1、B2、B3选择估值最小的局面,称为极小点。
Alpha-Beta搜索
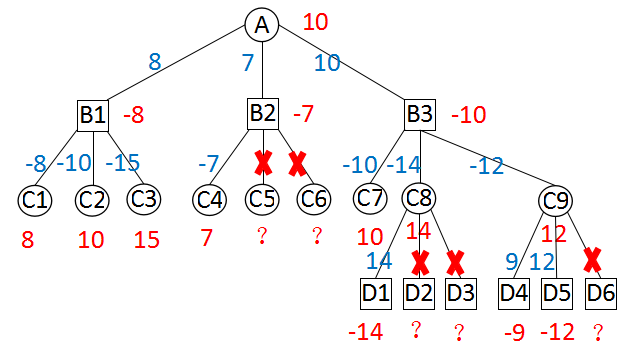
叶子节点(depth == 0),调用评估函数并返回分值
当前局面全部走法
在根节点,Alpha取负无穷,Beta取正无穷。当函数递归时,Alpha和Beta不但取负数而且要交换位置。Alpha表示当前搜索节点走棋一方搜索到的最好值,任何比它小的值对当前节点走棋方都没有意义。Beta表示对手目前的劣势,这是对手所能承受的最坏结果。Beta值越大,表示对方劣势越明显;Beta值越小,表示对方劣势也越小。在对手看来,他总是希望找到一个对策不比Beta更坏。如果当前节点返回Beta或比Beta更好的值,作为父节点的对方就绝不会选择这种策略。
准备深入研究的同学请到https://www.zcappp.cn/course/chess页面后,点击右侧的【克隆】按钮,把整个游戏复制一份随意玩弄更改。
更多教学视频请移步哔哩哔哩空间:https://space.bilibili.com/475645807,里面不仅有各种前端可视化案例演示和讲解,还有多个完整功能的网站应用案例的开发过程演示和讲解。

